3-Layered approach to organizing Terraform code
I’ll be presenting an opinionated view of organizing Terraform code in this post. Let’s take the scenario of creating an EKS cluster using Terraform. We shall first list down the resources we need to create:
- A VPC to house your cluster
- A list of security groups
- The EKS cluster itself
The naive and simple way to go about this is to have one tf file for each of these resources, and an outputs.tf for printing out the cluster details, [like this]. There’s nothing wrong about this per se, as the intent of this code is pedagogy, i.e. to demonstrate how to create an EKS cluster using Terraform. This is not easily reusable. Let’s say that another team wants to reuse the same code to create EKS clusters for themselves.
Now, we decide to “modularise” this, and rightly so. A Terraform module is a collection of resources grouped together, which can be reused. The EKS module now would look like this:

And all the other teams can use this module to create and manage EKS clusters. A few weeks later, we decide that we want to manage cluster IAM roles and create ELBs through this same module. We decide to add those resources to the module. Our module will now look more like this:

We can observe that the module isn’t as reusable as it was initially. For instance, if a team wants to use the module only for managing EKS, it can’t do so without stubbing out parameters for IAM roles and ELBs. This violates the “interface segregation principle”. Quoting from [SOLID],
clients should not be forced to implement a function they don’t need. Now, borrowing other concepts from SOLID, let’s see how we can reorganise this using the proposed new module structure.
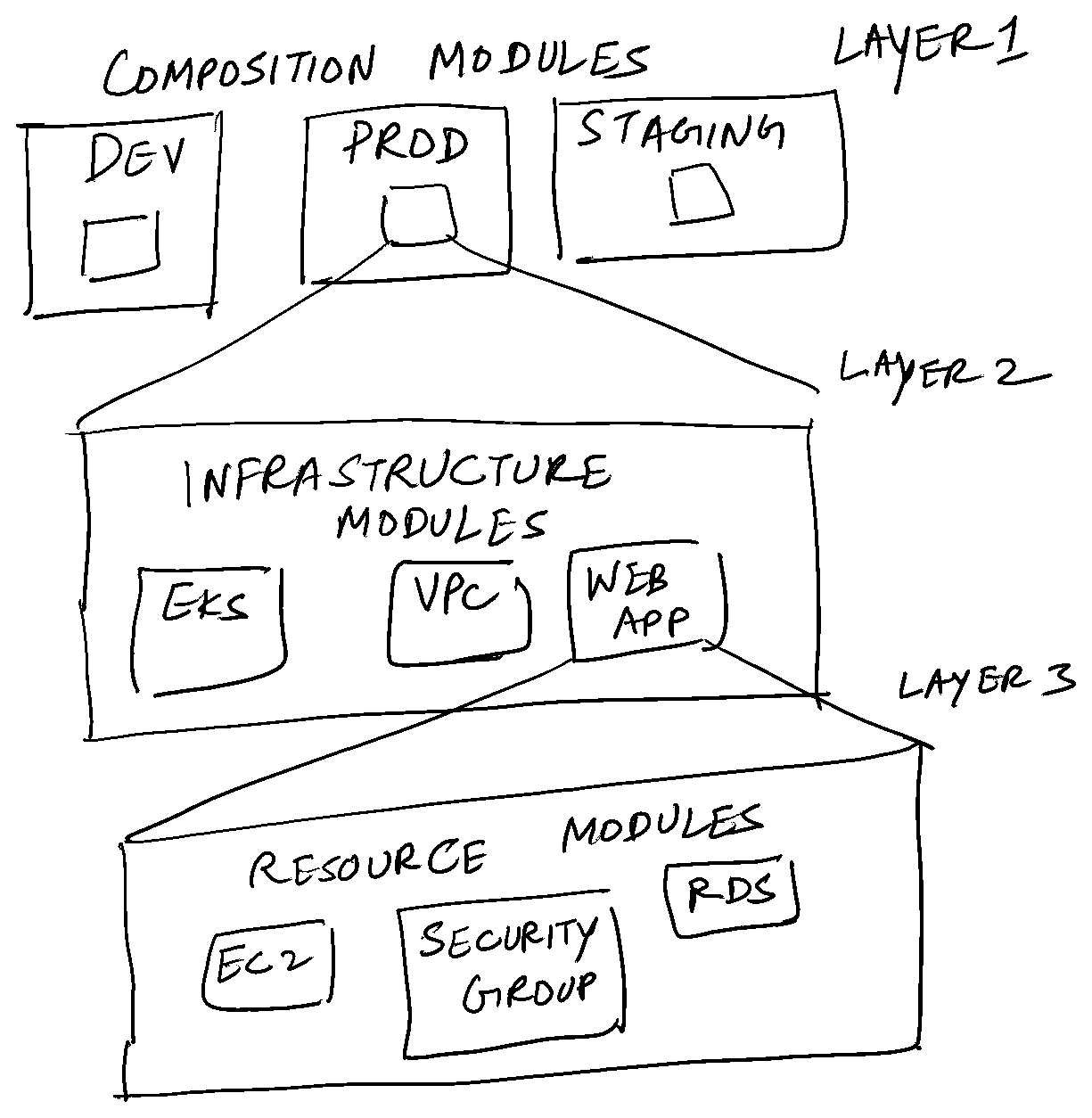
Resource modules #
The first layer/set of modules is called “resource modules”. These fall into one of 2 categories:
- the existing self-contained modules provided by official Terraform providers. A good example is the [S3 bucket module].
- Set of one or more modules wrapped into a single module created and maintained by you. An example of this would be a VPC module.
Infrastructure modules #
These are higher level abstractions of resource modules. They contain a set of related resource modules which are logically connected to each other. If you’re writing terraform code for a 3 tier web app, the “web app” is an infrastructure module consisting of the following resource modules: ec2, key pair, security groups, ELB, RDS and elasticache.
Composition modules #
Collection of infrastructure modules separated by context. Context could be different AWS accounts, different AWS regions or different kinds of environments(dev, prod etc.)
Conclusion and my thoughts #
I think this is a refreshing way to look at organising Tf modules. It ticks all boxes of SOLID design:
- Single responsibility, each module does only one thing.
- Open for extension, closed for modification. We can always extend a module to add new parameters. If we want to, say, use a Fargate profile to manage EKS resources, then we can write a new Fargate resource module layer and integrate it as an optional parameter in the infrastructure module layer.
- Liskov substitution principle. Not sure how this applies in the context of Terraform. But I’d define it loosely as any module in any layer can be replaced by another Tf module which has the same input.tf and output.tf.
- Interface segregation principle. Clients needn’t implement parts of the interface they don’t use.
- Dependency inversion. Each layer clearly exposes an interface to the layer above it. The details of a layer can be changed without affecting the layer above it. For example, we can change the vpc infrastructure module without affecting eks composition module in any way. Still, I feel the composition module layer to be redundant. It could be fulfilled by Terraform workspaces easily.